Check out this week’s Danger Zone interview with Chuck Jaffe of Money Life and MarketWatch.com.
I’m deviating from the norm this week. Instead of a stock, fund, or sector, I’m putting the electronic reporting language XBRL in the Danger Zone.
The purpose of XBRL is to make certain parts of SEC filings (and other business documents) machine readable, for example the financial statements. Ideally, the automated data gathering that XBRL enables would allow for more sophisticated analysis by regulators, analysts, and investors.
The SEC, under former Chairman Christopher Cox, mandated that this global standard for exchanging business information be adopted by publicly traded companies beginning in 2010.
Since New Constructs focuses on gathering financial data directly from filings, I have a strong interest in the progress of XBRL. We currently gather all the financial data ourselves because none of the data providers can supply either the quantity (ie footnotes) or quality of data that we need. If XBRL could supply all the data we need, it would make my business much more efficient. I am a big fan of XBRL and would like to see it succeed.
As of this year, all companies are required to submit their annual and quarterly reports in XBRL. As one might expect, we eagerly examined their filings. Our conclusion: XBRL is rife with issues and not usable.
In order for XBRL to serve as a substitute for manual data gathering, it must be 100% reliable in terms of presenting the correct information. XBRL is not worth the trouble if you have to go back and verify all the data manually anyway.
We did not expect XBRL to be 100% reliable in the first few years of its implementation, but we hoped by this time that it would be reliable at least for the easier data points like the financial statements. Instead, we found that a large number of companies were not able to get even the simplest data points correct in their 10-Q filings.
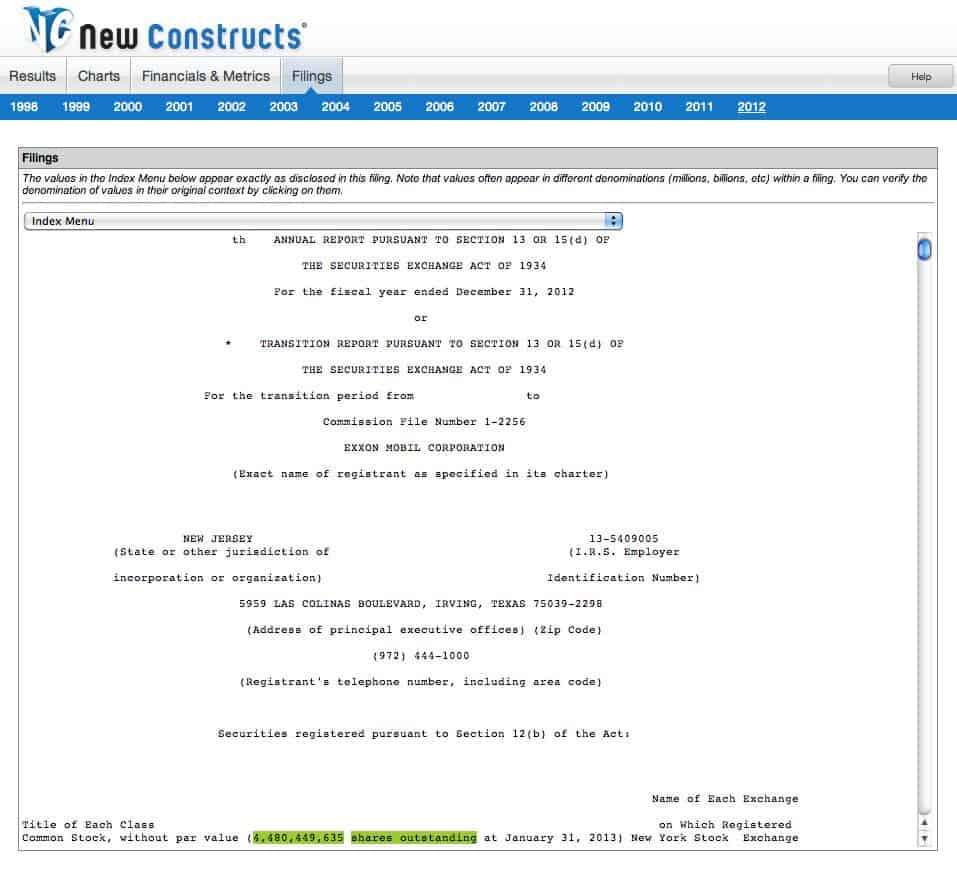
The “total shares outstanding” is one of the easiest data points to scrape manually from a regular 10-K or 10-Q filing. That data point shows up in the same place and in the same format for nearly every 10-K or 10-Q filing in the universe. The bottom of the first page will have the number of shares outstanding and the date on which the shares were counted (see an example here). A filing that gets this wrong is like a basketball player that can’t find the basket. How can you rely on them to do anything else right if they can’t execute such a simple task?
{kind=link}
Early in our analysis, we found errors so egregious and so often that we realized further analysis was not worthwhile. The errors involved both conflicting and wrong numbers and dates. Conflicting means the XBRL filing had different data than the text or HTML version of the filing or the header file from the SEC. Wrong means the data was incorrect or missing in all areas.
The data was not just off by a little bit. As you can see in Figure 1, the date could be months off, and in one case even over a year off.
Figure 1: XBRL Errors for the Date for Shares Outstanding
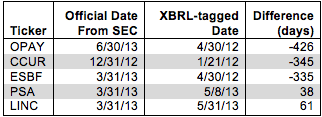 Sources: New Constructs, LLC and company filings
Sources: New Constructs, LLC and company filings
Figure 2 shows that share counts were sometimes off by millions or even missing entirely
Figure 2: XBRL Errors for Shares Outstanding
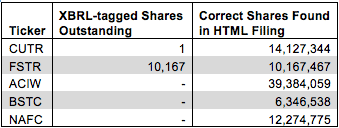 Sources: New Constructs, LLC and company filings
Sources: New Constructs, LLC and company filings
Click here for CIK and Accession numbers for the filings for the samples in Figures 1 and 2 as well as more examples. Don’t think that only smaller companies have these issues. Exxon Mobil (XOM) and Verizon (VZ) both had conflicting or wrong data as well.
It appears that no one is checking XBRL tags to make sure they are correct. The SEC has responsibility for enforcing XBRL but does not seem to consider it a priority. Right now, enforcement is so lax that many companies with incorrect XBRL tags don’t even realize they’re making mistakes.
This nonchalance surprises me a great deal. Based on a report on disclosure transgressions that I prepared for the Senate Banking Committee in 2009, the SEC is clearly not able to review in meaningful detail every filing submitted by companies. Their processes are almost entirely manual and based on word documents and letters to companies. From what I gathered back in 2009, the SEC had no database for analyzing and comparing financial data.
The SEC should welcome XBRL as a way to manage and analyze the mountain of data they need to evaluate. If they continue to allow blatantly wrong information, however, it becomes dead weight that complicates the process for filers and adds no value for regulators and investors. The potential utility of XBRL as a tool for regulators to fight fraud and investors to better analyze companies makes its numerous flaws that much more of a shame. I can only hope that the SEC realizes the value of XBRL and makes a commitment to ensuring the accuracy and validity of XBRL data.
In the meantime, thousands of disclosures on which the investing public relies flow through the SEC with very little to no review.
Sam McBride contributed to this article
Disclosure: David Trainer and Sam McBride receive no compensation to write about any specific stock, sector, or theme.